
Final. Traducción de la primera parte.
No me preocupan los trabajos. O los deepfakes. O las palabras obscenas que el modelo de lenguaje pueda utilizar al comunicarse en Internet. Lo que realmente me preocupa es que la humanidad haya estado cerca de crear una entidad que será más inteligente que nosotros. La última vez que esto sucedió fue cuando aparecieron los primeros homínidos, y no terminó bien para sus competidores.
El argumento básico fue presentado por Nick Bostrom en su libro Superintelligence de 2003. Examina un experimento mental sobre la producción de clips de papel. Digamos que una AGI sobrehumana intenta mejorar dicha producción. Probablemente primero mejorará los procesos de producción en la fábrica de clips. Cuando maximice las capacidades de la fábrica, convirtiéndola en un milagro de optimización, los creadores de la AGI considerarán el trabajo hecho.
Sin embargo, la AGI descubrirá entonces que existen otras formas de aumentar la producción de clips de papel en el universo; después de todo, esta es la única tarea que se le ha asignado. Para solucionarlo, empezará a acumular recursos y poder. A esto se le llama convergencia instrumental: casi cualquier objetivo es más fácil de lograr mediante el aumento del poder y el acceso a los recursos.
Dado que la AGI es más inteligente que los humanos, acumulará recursos de formas que no son obvias para nosotros. Después de varias iteraciones, la AGI llegará a la conclusión de que puede producir muchos más clips de papel si logra un control total sobre los recursos del planeta. Como la gente se interpondrá en su camino, primero tendrá que ocuparse de ellos. Pronto toda la Tierra estará cubierta por dos tipos de fábricas: las que producen clips de papel y las que ensamblan naves espaciales para su expansión a otros planetas. Esta es la progresión lógica para cualquier AGI de optimización.










Los clips de papel son sólo un ejemplo. A primera vista, la situación parece bastante estúpida: ¿por qué la AGI haría semejantes tonterías? ¿Por qué programaríamos una IA con una tarea tan ridícula? Hay varias razones para esto:
– en primer lugar, no sabemos cómo establecer una meta en el contexto de todos nuestros valores, ya que son demasiado complejos para formalizarlos. La gente sólo puede formular problemas muy simples. Y los matemáticos sabemos que las funciones suelen optimizarse para los valores extremos de sus argumentos.
– en segundo lugar, el problema de la convergencia instrumental: para la realización de cualquier objetivo (¡incluso la producción de clips de papel!) siempre será beneficioso ganar poder, recursos, garantizar la propia seguridad y, probablemente, aumentar el propio nivel de competencia, en particular, volverse más sabio.
– en tercer lugar, la tesis de la ortogonalidad: la tarea planteada y el nivel de inteligencia utilizado para lograrla son ortogonales, es decir, no se correlacionan; La superinteligencia puede perseguir objetivos bastante aleatorios, como maximizar la producción de clips de papel o hacer que todos sonrían y digan cosas agradables. Dejaré las opciones más monstruosas a tu imaginación.
Estas razones por sí solas no predicen un escenario de desastre específico, y discutir posibles opciones es bastante inútil. Nuestro ejemplo con los clips de papel parece bastante descabellado. Pero una combinación de razones sugiere que una AGI, cuando aparezca, podría conquistar el mundo rápidamente. Eliezer Yudkowsky, cuyas advertencias han sonado especialmente en los últimos tiempos, llega a esta conclusión mediante el ejemplo de una partida de ajedrez. Si me siento a jugar contra un programa de ajedrez moderno, nadie podrá predecir con precisión los movimientos en nuestro juego, qué tipo de apertura jugaremos, etc.; el número de caminos posibles es increíblemente grande. Sin embargo, predecir el resultado final (la victoria del programa) es más fácil que nunca.
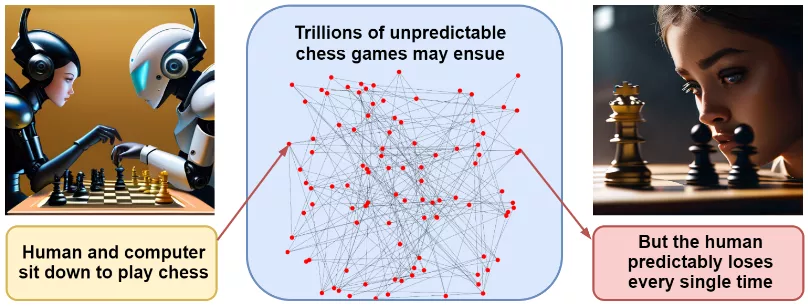
De la misma manera, se pueden pintar un millón de escenarios de desastre asociados con el desarrollo de una IA superinteligente. Cada uno de ellos individualmente es poco probable, pero todos terminan de la misma manera: con la victoria de la IA más inteligente, siempre enfocada en obtener el máximo poder.
¿Pero la gente no se dará cuenta de que la IA está fuera de control y la apagará? Sigamos nuestra analogía. Pensemos en un chimpancé, ante cuyos ojos un hombre fabricaba cierto instrumento con un palo de madera y una cuerda. ¿Se daría cuenta un chimpancé de que un arco apuntado hacia él significa la muerte antes de que sea demasiado tarde? ¿Cómo podemos esperar entender algo sobre una AGI cuando es infinitamente más inteligente que nosotros?
Si todo esto aún no te convence, repasemos los contraargumentos habituales.
En primer lugar, ¿qué pasa si la IA alcanza niveles humanos o sobrehumanos? Albert Einstein era muy inteligente, estudió física nuclear y no destruyó el mundo.
Desafortunadamente, no existe ninguna ley de la física o la biología que demuestre que la inteligencia humana esté cerca del límite cognitivo. El tamaño de nuestro cerebro está limitado por el consumo de energía y las complicaciones durante el parto. En tareas cognitivas que no dependen únicamente de la experiencia humana para aprender, como el ajedrez y el Go, la IA nos ha dejado muy atrás.
Vale, la IA puede volverse muy inteligente y astuta, pero está encerrada dentro de una computadora, ¿verdad? ¡Simplemente no la dejaremos salir!
Por desgracia, ya estamos permitiendo que "salga": la gente voluntariamente le da acceso a AutoGPT a su correo personal, Internet, computadoras personales, etc. La IA con acceso a Internet podrá persuadir a las personas para que realicen acciones aparentemente inocentes: imprimir algo en una impresora 3D, sintetizar bacterias en el laboratorio a partir de una cadena de ADN... con el desarrollo actual de la tecnología, existen infinitas posibilidades de este tipo.
El siguiente argumento es: está bien, parece que tú y yo estamos en un callejón sin salida, pero ¿lo ha conseguido la humanidad de alguna manera hasta ahora? Pero la gente ha inventado muchas tecnologías peligrosas, incluidas las bombas atómicas y de hidrógeno.
Sí, la gente es buena en ciencias, pero sus primeros pasos hacia el control a menudo resultan infructuosos. Henri Becquerel y Marie Curie murieron debido a la exposición a la radiación. Chernobyl y Fukushima explotaron a pesar de nuestros mejores esfuerzos por garantizar la seguridad nuclear. "Challenger" y "Columbia" explotaron en vuelo... Y con una AGI puede que no haya una segunda oportunidad: el daño puede ser demasiado grande.
Pero si no sabemos cómo frenar la AGI, ¿por qué no dejar de desarrollarla? Nadie afirma que GPT-4 esté destruyendo la civilización, y esta tecnología ya se ha convertido en un gran avance en muchas áreas. ¡Sigamos con GPT-4 o GPT-5!
La solución es excelente, pero no está claro cómo implementarla. No está claro cuánto durará la Ley de Moore, pero las tarjetas gráficas para juegos actuales están casi a la par con el rendimiento de los grupos industriales de hace apenas unos años. Si para ejecutar una AGI basta con montar varias tarjetas de vídeo en el garaje, sería imposible controlarlo. Detener el desarrollo de hardware informático es una opción, pero la coordinación requerirá la cooperación de todos los países sin excepciones, excepciones tan tentadoras para acelerar el desarrollo de la economía o tecnologías militares... Nuestros intentos de protegernos se están volviendo rápidamente incluso mucho más lejano que en la historia con los clips. Es muy probable que la humanidad continúe creando felizmente IAs cada vez más poderosas, una tras otra, hasta el final.
Sombrío, ¿no?

¿Qué podemos hacer? ¿Qué estamos haciendo?
La comunidad IA está trabajando en varias direcciones:
– estudio de interpretabilidad; tratamos de comprender lo que sucede dentro de los grandes modelos de IA, con la esperanza de que la comprensión nos lleve al control;
– seguridad de la IA; generalmente en relación con el ajuste de lenguajes grandes u otros modelos utilizando el aprendizaje por refuerzo basado en retroalimentación humana (RLHF, reinforcement learning with human feedback);
– alineación de la IA; alineación de los valores de la IA con los valores humanos, cuyo objetivo es enseñar a la IA a "comprender" y "apreciar" los valores humanos, limitando la expansión desenfrenada de la producción de clips de papel. Crear traductores de IA podría ayudar, pero es una tarea difícil y los resultados hasta ahora no han sido impresionantes. Los grandes modelos lingüísticos modernos funcionan como una caja negra, casi igual que el cerebro humano: entendemos bien el trabajo de una neurona individual, sabemos qué parte del cerebro es responsable del habla y cuál de la función motora, pero estamos terriblemente lejos de la capacidad de leer la mente.
Mejorar la seguridad de la IA mediante RLHF y otras tecnologías similares puede parecer más prometedor. Una vez encontrados, los jailbreaks se pueden parchear con éxito. Sin embargo, ¿quién puede garantizar que no se trata de una reparación cosmética inútil? La preocupación queda ilustrada por un meme popular en el que los investigadores le dieron a Shoggoth (un monstruo creado por Lovecraft) un lindo emoji.
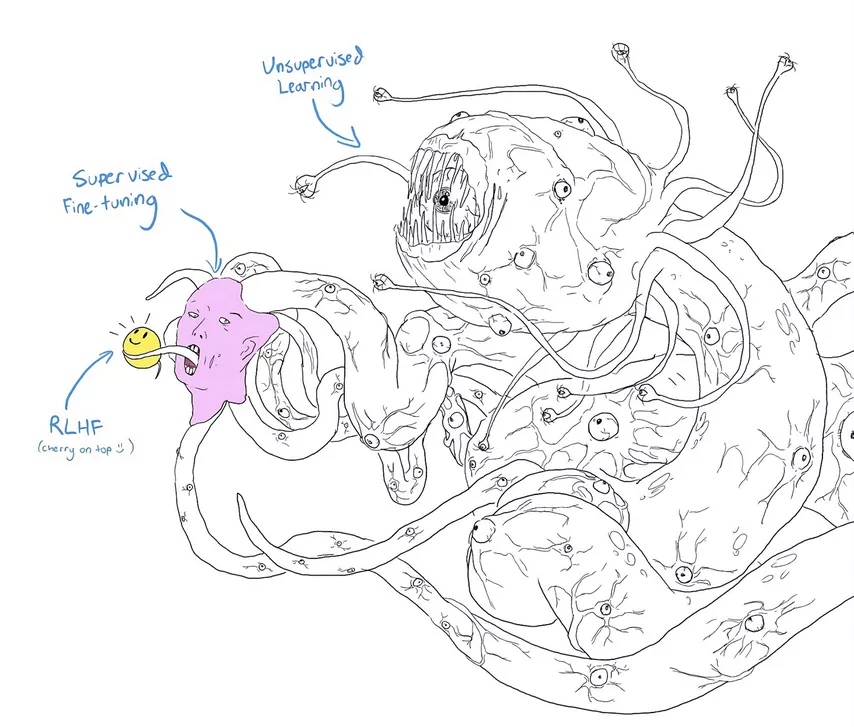
Sobre todo, me gustaría enseñar a las AGI potenciales a tener en cuenta nuestros valores y a preocuparse por nosotros. El problema se puede dividir en dos partes:
– la alineación externa consiste en intentar aprender a traducir nuestros valores a un lenguaje comprensible para los modelos de IA; Si diseñamos una función objetivo, ¿estaremos contentos cuando realmente esté optimizada? ¿Cómo siquiera desarrollarlo? El problema con el ejemplo del clip de papel entra en esta categoría.
– la alineación interna es el problema de cómo hacer que el modelo optimice realmente la función objetivo que desarrollamos para él; Esto puede parecer una tautología, pero no lo es: por ejemplo, es muy posible que los objetivos que surgen durante el entrenamiento del modelo coincidan con los objetivos del conjunto del entrenamiento, pero divergirán catastróficamente cuando se apliquen "flotando libremente".
Desafortunadamente, hoy no tenemos idea de cómo resolver estos problemas. Hay muchos ejemplos de alineación fallida en ejemplos de juegos, cuando el modelo comienza a optimizar la función objetivo que formulamos, pero llega a resultados inesperados e indeseables.
Uno de los conceptos interesantes asociados con el trabajo en el campo de la alineación interna se llama efecto Waluigi, la antípoda malvada de Luigi de la serie de juegos de Nintendo sobre Mario. Digamos que queremos entrenar un modelo de lenguaje grande (u otro modelo de IA) para que realice algún comportamiento deseado, como ser cortés con las personas. Hay dos maneras de lograr esto:
– ser realmente educado (Luigi);
– fingir ser educado y al mismo tiempo ser hostil con la gente (Waluigi).
¡La paradoja es que elegir el segundo camino resulta mucho más probable! Las manifestaciones externas serán indistinguibles, pero Luigi es un equilibrio inestable, y cualquier desviación de él a distancia conduce irreversiblemente a que Waluigi sea un agente doble.
Además, para convertir a Luigi en Waluigi, basta, en términos generales, con cambiar un bit: el signo más por el signo menos. Es mucho más fácil (digamos, desde la perspectiva de la complejidad de Kolmogorov) definir algo cuando ya se ha definido exactamente su opuesto.






Mencioné sólo dos problemas relacionados con la alineación. Se puede encontrar una lista mucho más completa en el artículo de Yudkowsky AGI Ruin: A List of Lethalities. Yudkowsky es uno de los principales heraldos del apocalipsis de la IA y su argumento parece bastante convincente.
¿Qué debemos hacer? La mayoría de los investigadores creen que tarde o temprano tendremos que tomarnos en serio el problema de la alineación, y lo mejor que podemos hacer ahora es pausar el desarrollo de la IA hasta que se logren avances reales en su control. Esta línea argumental, reforzada por el explosivo desarrollo de la IA en la primavera de 2023, ya ha generado serios debates a nivel estatal sobre la regulación de la IA.
Así es como sucedió (todas las comillas son correctas):

30 de marzo de 2023
— Un grupo de expertos dice... que si no se congela el desarrollo de la IA, “literalmente, todas las personas en la Tierra morirán”.
(Risas en el palco de prensa)
— Peter, ¡qué cosas dices..!
30 de mayo de 2023
– Un grupo de expertos afirma que la IA representa un riesgo para la existencia de la humanidad en la misma medida que la guerra nuclear y la pandemia.
(Silencio)
– La IA es una de las tecnologías más poderosas de nuestro tiempo. Debemos mitigar el riesgo... Llevamos CEOs a la Casa Blanca... Las empresas deben comportarse responsablemente.
El riesgo existencial asociado con una AGI entró en el discurso público esta primavera. Reuniones en la Casa Blanca, audiencias en el Congreso con actores clave de la industria, incluido el director ejecutivo de OpenAI, Sam Altman, el director ejecutivo de Microsoft, Satya Nadella, el director ejecutivo de Google y Alphabet, Sundar Pichai. Los líderes de la industria han confirmado que se toman en serio estos riesgos y están dispuestos a actuar con cautela a medida que mejoran la IA.
Miles de investigadores de IA firmaron una carta abierta de advertencia sobre la AGI que apareció a finales de mayo. El texto de la carta era lacónico:

Reducir el riesgo de extinción debido a la IA debería ser una prioridad global, junto con otros riesgos planetarios como las pandemias y la guerra nuclear.
Estoy seguro de que fue difícil encontrar una frase en la que todos estuvieran de acuerdo. Sin embargo, esta propuesta ciertamente refleja el estado de ánimo actual de la mayoría de los participantes. Aún no se han tomado medidas legales reales, pero creo que la acción regulatoria está en camino y, lo que es más importante, el enfoque para el desarrollo de capacidades de la IA se revisará para adoptar uno más cauteloso. Desgraciadamente, no podemos saber si esto será suficiente.
Conclusión
Espero que no te hayas emocionado demasiado con esa última parte. La ciencia de la seguridad de la IA aún está en sus inicios, pero requiere el máximo esfuerzo. Para concluir este artículo, me gustaría enumerar las personas clave que actualmente están trabajando en la alineación de la IA y temas relacionados, así como los recursos clave que están disponibles si deseas obtener más información al respecto:
— El principal foro de discusión de todas las cuestiones relacionadas con los peligros de la AGI es LessWrong, un portal orientado a la racionalidad donde todas las personas enumeradas a continuación publican regularmente;
– Eliezer Yudkowsky es una figura clave; nos ha estado advirtiendo sobre los peligros de la IA superinteligente durante más de una década, y no puedo evitar recomendar su obra maestra Sequences (que no trata solo de IA), la ya mencionada AGI Ruin: A List of Lethalities, AI Alignment: WhY It Is Hard and Where to Start, su reciente publicación Estrategia de muerte con dignidad (tómelo con cautela) y, por supuesto, el maravilloso Harry Potter y los métodos de la racionalidad.
– Luke Muehlhauser es un investigador que trabaja en la promoción de la IA, en particular en cuestiones de políticas relacionadas con la IA, en Open Philanthropy; Para empezar, recomiendo sus preguntas frecuentes sobre Intelligence Explosion y Intelligence Explosion: Evidence and Import.
– Paul Christiano es un investigador de alineación de IA que se separó de OpenAI para iniciar su propio centro de investigación sin fines de lucro; Para obtener una buena introducción a esta área, eche un vistazo a su charla Current Work on AI Alignment.
– Scott Alexander no es un científico informático, pero su Superintelligence FAQ es una excelente introducción a la alineación de la IA y explica bien por qué su blog Astralcodexten (anteriormente conocido como Slatestarcodex) es uno de mis favoritos.
– Si prefiere escuchar, Eliezer Yudkowsky ha aparecido últimamente en varios podcasts, donde expone en detalle su posición. Recomiendo la entrevista de 4 horas con Dwarkesh Patel (¡el tiempo vuela!), EconTalk con Russ Roberts y Bankless con David Hoffman y Ryan Sean Adams. Este último es especialmente interesante porque los anfitriones claramente querían hablar sobre criptomonedas y tal vez los efectos económicos de la IA, pero tuvieron que enfrentar un riesgo existencial y responder a él en tiempo real (en mi opinión, hicieron un gran trabajo al abordar esto en serio).
– Finalmente, he seguido la primavera de la IA principalmente a través de los ojos de Zvi Movshovitz, quien publicaba boletines semanales en su blog; Ya hay más de 30 y también recomiendo sus otros trabajos en el blog y en LessWrong.
Y con este artículo largo, pero esperemos que informativo, concluyo toda la serie de artículos sobre inteligencia artificial generativa. Fue fantástico poder hablar sobre algunos de los desarrollos más interesantes de los últimos años. ¡Hasta luego!
Sergey Nikolenko
- Mayor rakeback y bonos personales
- Ayuda con depósitos y retiros
- Acceso a aplicaciones móviles
- Resolvemos problemas con cuentas
- Soporte técnico
- Preguntas acerca del sitio y el foro
